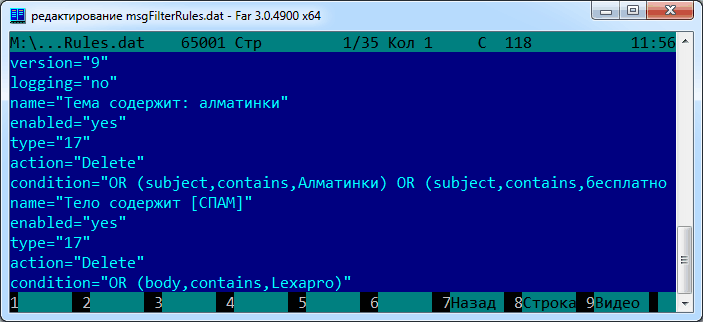
Вордпресс давно горит красненьким: обновите свой PHP. Ну и хрен с тобой — гори!
Но тут, как беременному, приспичило селёдки перевести WP-сайты на статику и убрать WP с сервера. А модный плагин WP2Static в открытую шантажирует – работаю только на PHP 7.
Ну давай, блин, обновляться!..
Начал с локальной машины, где всё крутится на Denwer 3 (A2.2.22, P5.3.13, M5.5).
Сначала накатил PHP 5.6.19 + Apache 2.40 отсюда и затем повысил PHP до 5.6.40 из архива дистрибутивов по этой инструкции (ну а вдруг?! 😉 ). Вордпресс не оценил.
Оокей! Едем дальше.
Тогда старый сервер отправил в архив и перешёл на новую сборку Denwer (Apache 2.4, PHP 7, MySQL 5.7).
Вордпресс обновился, WP2Static подтянулся, тестовый сайт загнал в статику.
Супер, чо!
Но голос капитана Зелёного в моей голове:
И понеслась… 😀
Запуск OpenGoo 1.3.1 в 2019
Нежно люблю дерево задач из древнего OpenGoo.
В своё время искал, перепробовал многое, но остановился на этом комбайне, из которого юзаю одну только функциональность – дерево задач.
Оно умеет назначать задачи разным юзерам, выращивать их деревом, создавать шаблоны из выращенных деревьев.
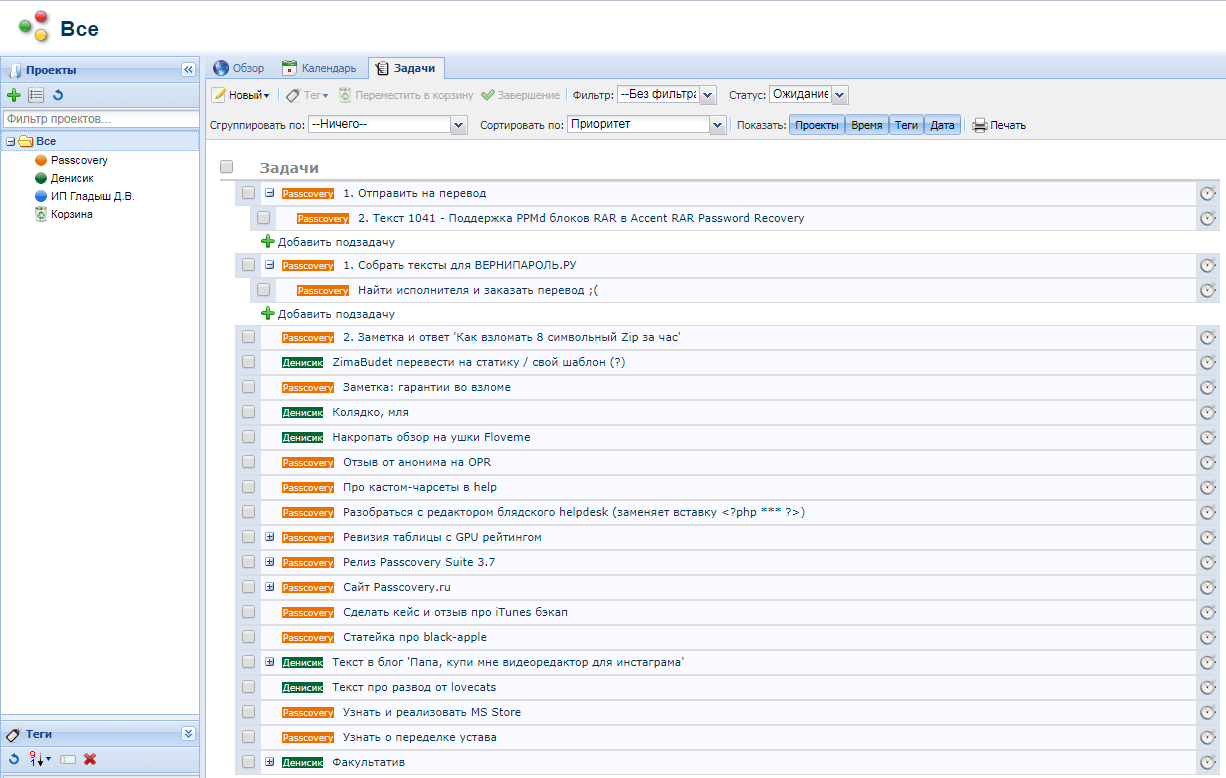
Мне удобно делать релизы и публикации по чеклисту из шаблонов, накидывать туда все списки дел, дробить их на подзадачки и потом с наслаждением удалять их по мере выполнения. 😉
Хреновина ресурсоёмкая, по нагрузке на сервер не супер-оптимизированная, насколько я могу судить по периодическому 500 ответу сервака.
Но вот привык.
А на новом сервере оно не взлетело.
Суть, как и во многом далее – в использовании в OpenGoo устаревшего драйвера mysql (который в PHP7 выпилили) и отсутствие обратной совместимости с новым mysqli, который идёт с PHP 7.
ОКей, починяю этот примус и запускаю древнючий OpenGoo 1.3.1 в 2019 году 😉 :
-
- Перевёл все обращения к MySQL базе под формат mysqli. Для этого установил на сервер скрипт, путь к директории – относительно сервера:
/home/бла-бла-бла/convert
- Указал в конфиге OpenGoo использовать mysqli адаптер, вместо mysql. По инструкции:
define('DB_ADAPTER', 'mysqli'); - Ну и собсно добавил сам адаптер-класс в папку
/opengoo/environment/library/database/adapters
- Перевёл все обращения к MySQL базе под формат mysqli. Для этого установил на сервер скрипт, путь к директории – относительно сервера:
И оно завелось (на самом деле нет).
Где-то валится при создании шаблона. Погружаться в дебри того кода желания нет и потому из говна и палок сделал костыль: импортировал базу в старый денвер, создал там себе пачку заготовок под шаблоны и импортировал базу обратно в новый денвер. 😉
Запуск GeoIP для PHP5
yum install php-pear gcc make php-devel – установит php-pear пакет для компилирования исходниковyum install GeoIP GeoIP-data GeoIP-devel – установит пакеты geoippecl install geoip – соберёт PECL библиотеку geoip.soecho "extension=geoip.so" > /etc/php.d/geoip.ini – включит библиотеку после рестарта апача.
Если есть альтернативный PHP (у меня это PHP 7.3), то под него собираем свой модуль:
/opt/php73/bin/pecl install geoip-1.1.1 – соберёт PECL библиотеку geoip.so
И прописываем в своих php.ini его подключение. Поскольку это альтернативный php, то php.ini может быть для каждого юзера своя. Смотри в папке юзера.